[JPA] N + 1 문제 2 (fetch join 최적화)
Intro
앞선 게시물에서 N+1문제가 무엇인지 알아보고 기본적으로 지연 로딩으로 설정하는 이유에 대해서 알아봤다.
SQL을 조금 알고 있는 사람이라면 앞 게시물에 나오는 쿼리를 보고 join을 사용해서 단 한번의 쿼리로 다 가져올 수 있지 않을까 생각이 들것이다.
오늘은 JPQL에서 join을 최적화해서 할 수 있는 fetch join에 대해서 알아보자.
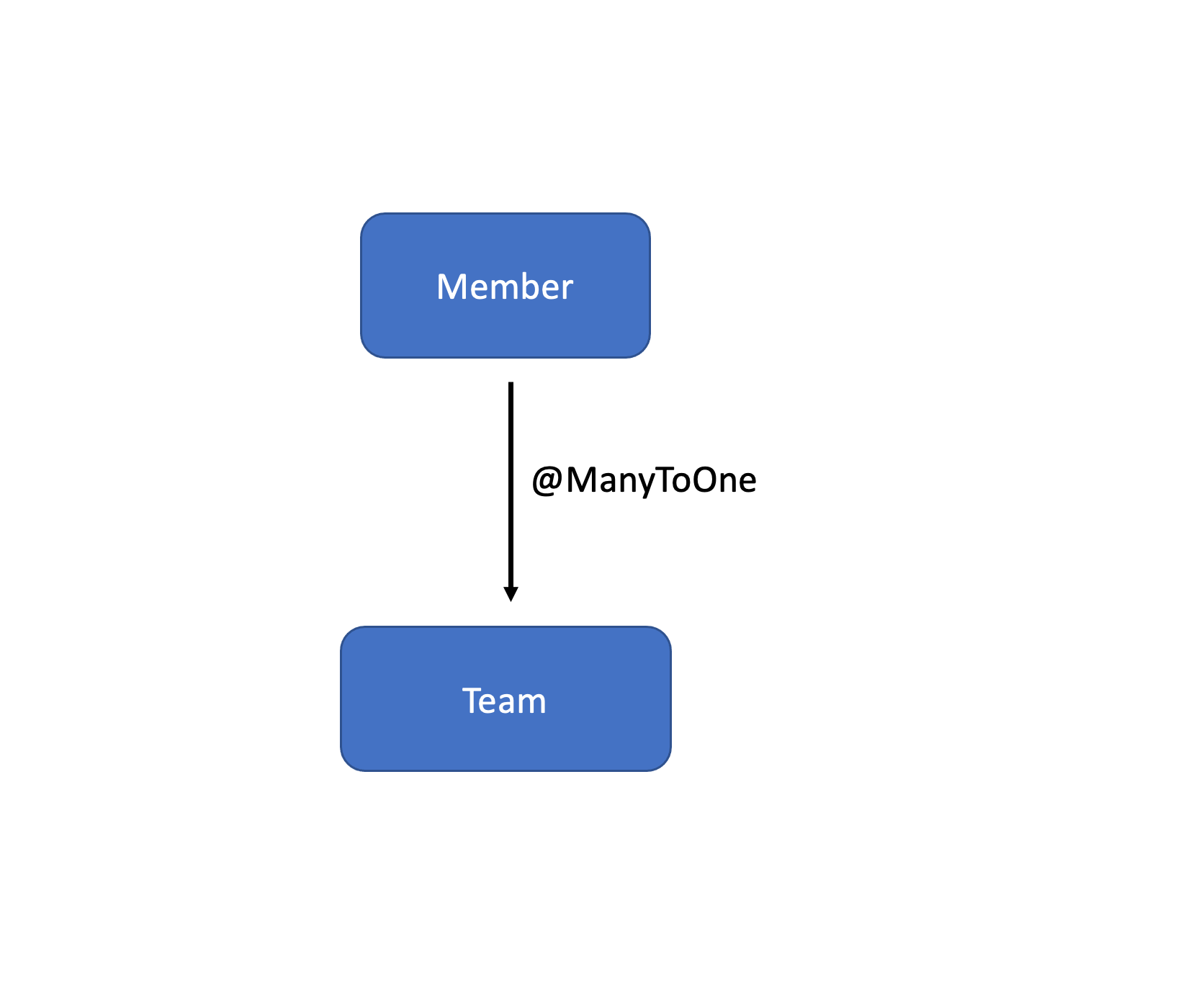
연관관계는 저번이랑 동일하게 위와 같다고 가정한다.
fetch join
문제 발생
저번이랑 동일하게 Member를 가져올 때 Team도 함께 가져오는 상황이라고 가정하자.
이를 JPQL로 표현하면 다음과 같다.
select m from Member m;지연 로딩을 사용하면 이렇게 가져온 데이터에서 .getTeam 같은 메소드를 이용해 team의 데이터가 필요한 시점에 team을 호출하는 쿼리가 나간다.
즉 각각의 Member의 Team을 조회하려면 각각의 Member를 루프 돌면서 Team 프록시 객체를 통해 조회하는 쿼리가 나간다.
(첫번째 Member를 가져오는 쿼리 1개) + (각 Member의 Team을 조회하는 쿼리 N개) == N+1문제
문제 해결
똑같은 상황을 fetch join을 통해서 해결하면 다음과 같다.
select m from Member m join fetch m.team;위 JPQL은 아래의 SQL로 번역된다.
SELECT M.*, T.* FROM MEMBER M
INNER JOIN TEAM T ON M.TEAM_ID=T.ID즉, fetch join을 사용하면 한 번에 엔티티를 조회해서 필요한 데이터를 가져오는 것이다. 그럼 루프를 돌아서 추가적인 쿼리를 날리지 않고 한번에 데이터를 가져와서 컬렉션에 저장해놓을 수 있다.
Fetch Join과 일반 Join의 차이?
그냥 join을 실행하면 sql join은 되는데 select 조회 문에 T.* 이 안들어간다고 생각하면 된다. 그리고 지연 로딩식으로 해당 데이터가 필요할 때 쿼리가 날라간다.
Collection Fetch join
위와 같은 다대일 관계라면 fetch join을 써도 아무런 문제가 없을 것이다. 하지만 만약 일대다(@XXToMany)라면 어떻게 될까?
만약 Team을 조회하는데 Member를 가져온다고 생각해보자.
select t from Team T join fetch t.member;위 JPQL은 아래의 SQL로 번역될 것이다.
SELECT * FROM TEAM T
INNER JOIN MEMBER M ON T.team_id = m.team_idSQL JOIN은 컬럼들을 합쳐서 하나의 테이블을 생성해서 넘겨준다고 생각하면 된다. 그렇다면 Team의 컬럼들과 Member의 컬럼들이 합쳐지게 된다. 그럼 1:N 관계이므로 데이터가 N개 나와서 1에 해당하는 값들이 중복해서 나오는 경우가 발생한다.
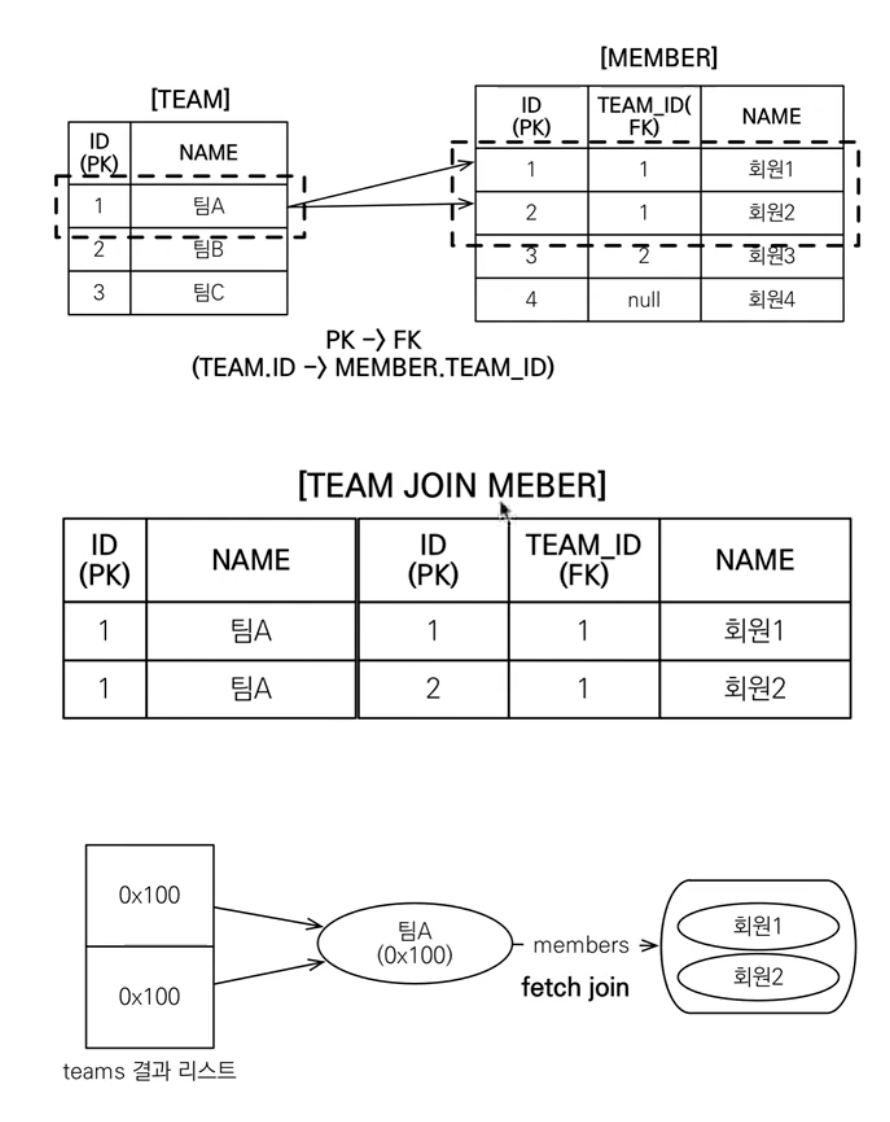
팀 A는 1개이지만 Member가 2명이므로 2 Row가 나온다.
이 문제는 distinct fetch join을 사용해서 해결하면 된다.
JPQL로 보면 다음과 같다
select distinct t from Team T join fetch t.member;JPQL의 distinct는 두 가지 기능이 있다.
- SQL문에 distinct를 추가한다.
- Collection안에 있는 중복을 엔티티를 제거한다.
위의 두 기능 덕분에 중복을 제거한 데이터를 얻을 수 있다.
마무리
지금까지 fetch join을 이용해서 N+1문제를 해결하는 방법에 대해서 공부해봤다. 대부분의 문제는 fetch join으로 해결이 가능하다. 하지만 collection을 fetch join할 때는 페이징을 할 수 없다는 단점이 있다. 이를 항상 염두해두고 사용하자!